
撰文:Geng Kai、Eric,DFG
自 2023 年以来,AI 和 DePIN 都是 Web3 中的热门趋势,其中 AI 的市值为300 亿美元,而 DePIN 的市值为230 亿美元。这两个类别非常庞大,每个类别都涵盖了各种不同的协议,这些协议服务于不同的领域和需求,应该单独涵盖。然而,本文旨在讨论两者之间的交集,并研究该领域协议的发展。
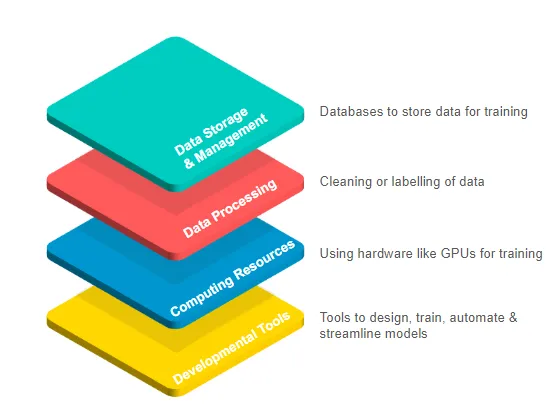
在 AI 技术堆栈中,DePIN 网络通过计算资源为 AI 提供实用性。大型科技公司的发展导致GPU 短缺,这导致其他正在构建自己的 AI 模型的开发人员缺乏足够的 GPU 进行计算。这通常会导致开发人员选择中心化云提供商,但由于必须签署不灵活的长期高性能硬件合同,导致效率低下。
DePIN 本质上提供了一种更加灵活且更具成本效益的替代方案,它使用代币奖励来激励符合网络目标的资源贡献。人工智能中的 DePIN 将 GPU 资源从个人所有者众包到数据中心,为需要访问硬件的用户形成统一的供应。这些 DePIN 网络不仅为需要计算能力的开发人员提供可定制性和按需访问,还为可能难以通过闲置获利的 GPU 所有者提供额外收入。
市场上有如此多的 AI DePIN 网络,可能很难识别它们之间的差异并找到所需的正确网络。在下一部分中,我们将探讨每种协议的作用以及它们试图实现的目标,以及它们已经实现的一些具体亮点。
这里提到的每个项目都有一个类似的目的——GPU 计算市场网络。本文这一部分的目的是研究每个项目的亮点、它们的市场重点以及它们所取得的成就。通过首先了解它们的关键基础设施和产品,我们可以深入了解它们之间的差异,这将在下一节中介绍。
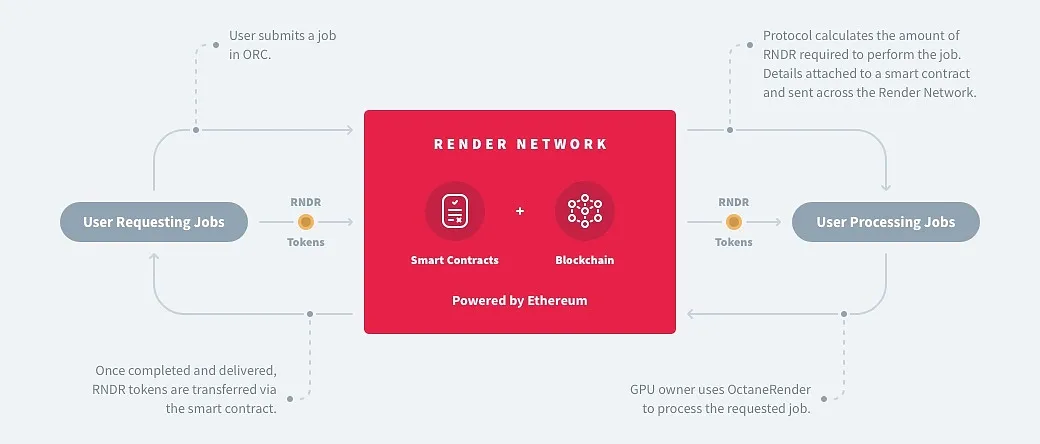
Render是提供 GPU 计算能力的 P2P 网络的先驱,之前专注于为内容创作渲染图形,后来通过集成Stable Diffusion等工具集,将其范围扩展到包括从神经反射场 (NeRF) 到生成 AI 的 AI计算任务。
有趣之处:
由拥有奥斯卡获奖技术的云图形公司 OTOY 创立
GPU 网络已被派拉蒙影业、PUBG、星际迷航等娱乐行业的大公司所使用
与 Stability AI 和 Endeavor 合作,利用 Render 的 GPU 将他们的 AI 模型与 3D 内容渲染工作流程相集成
批准多个计算客户端,集成更多 DePIN 网络的 GPU
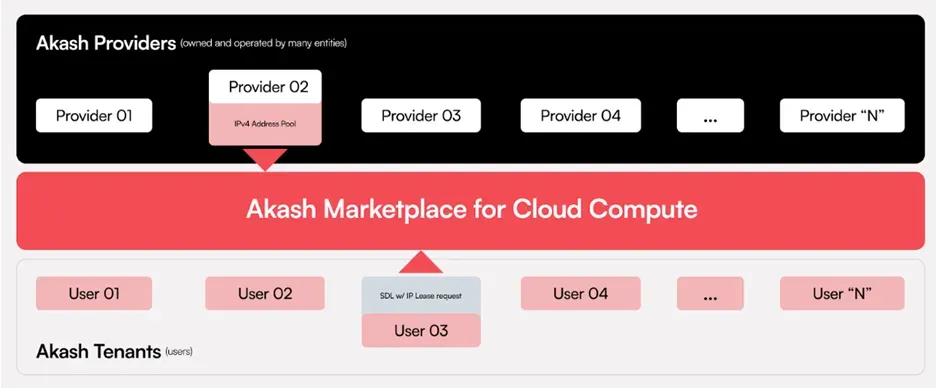
Akash将自己称为“托管版 Airbnb”,将自己定位为支持存储、GPU 和 CPU 计算的传统平台(如 AWS)的“超级云”替代品。利用Akash 容器平台和Kubernetes 管理的计算节点等开发人员友好型工具,它能够跨环境无缝部署软件,从而能够运行任何云原生应用程序。
有趣之处:
针对从通用计算到网络托管的广泛计算任务
AkashML 允许其 GPU 网络在 Hugging Face 上运行超过 15,000 个模型,同时与 Hugging Face 集成
Akash 上托管着一些值得注意的应用程序,例如 Mistral AI 的 LLM 模型聊天机器人、Stability AI 的SDXL文本转图像模型,以及 Thumper AI 的新基础模型AT-1
构建元宇宙、人工智能部署和联邦学习的平台正在利用 Supercloud
io.net提供对分布式 GPU 云集群的访问,这些集群专门用于 AI 和 ML 用例。它聚合了来自数据中心、加密矿工和其他去中心化网络等领域的 GPU。该公司之前是一家量化交易公司,在高性能 GPU 价格大幅上涨后,该公司转向了目前的业务。
有趣之处:
其 IO-SDK 与 PyTorch 和 Tensorflow 等框架兼容,其多层架构可根据计算需求自动动态扩展
支持创建3 种不同类型的集群,可在 2 分钟内启动
强有力的合作努力,以整合其他 DePIN 网络的 GPU,包括 Render、Filecoin、Aethir 和 Exabits
Gensyn提供专注于机器学习和深度学习计算的 GPU 计算能力。它声称与现有方法相比,通过结合使用诸如用于验证工作的学习证明、用于重新运行验证工作的基于图形的精确定位协议以及涉及计算提供商的质押和削减的 Truebit 式激励游戏等概念,实现了更高效的验证机制。
有趣之处:
预计 V100 等效 GPU 的每小时成本约为 0.40 美元/小时,从而大幅节省成本
通过证明堆叠,可以对预先训练的基础模型进行微调,以完成更具体的任务
这些基础模型将是去中心化的、全球拥有的,除了硬件计算网络之外还提供额外的功能
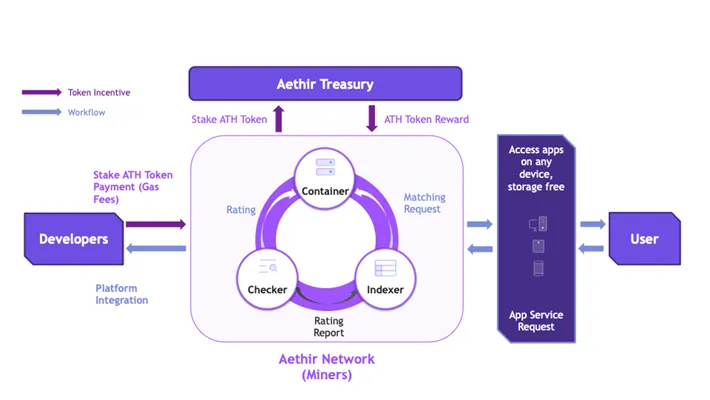
Aethir专门搭载企业 GPU,专注于计算密集型领域,主要是人工智能、机器学习 (ML)、云游戏等。其网络中的容器充当执行基于云的应用程序的虚拟端点,将工作负载从本地设备转移到容器,以实现低延迟体验。为了确保为用户提供优质服务,他们根据需求和位置将 GPU 移近数据源,从而调整资源。
有趣之处:
除了人工智能和云游戏,Aethir 还扩展到云手机服务,并与 APhone 合作推出去中心化的云智能手机
与 NVIDIA、Super Micro、HPE、富士康和 Well Link 等大型 Web2 公司建立了广泛的合作伙伴关系
Web3 中的多个合作伙伴,例如 CARV、Magic Eden、Sequence、Impossible Finance 等
Phala Network充当 Web3 AI 解决方案的执行层。其区块链是一种无需信任的云计算解决方案,通过使用其可信执行环境 (TEE) 设计来处理隐私问题。其执行层不是用作 AI 模型的计算层,而是使 AI 代理能够由链上的智能合约控制。
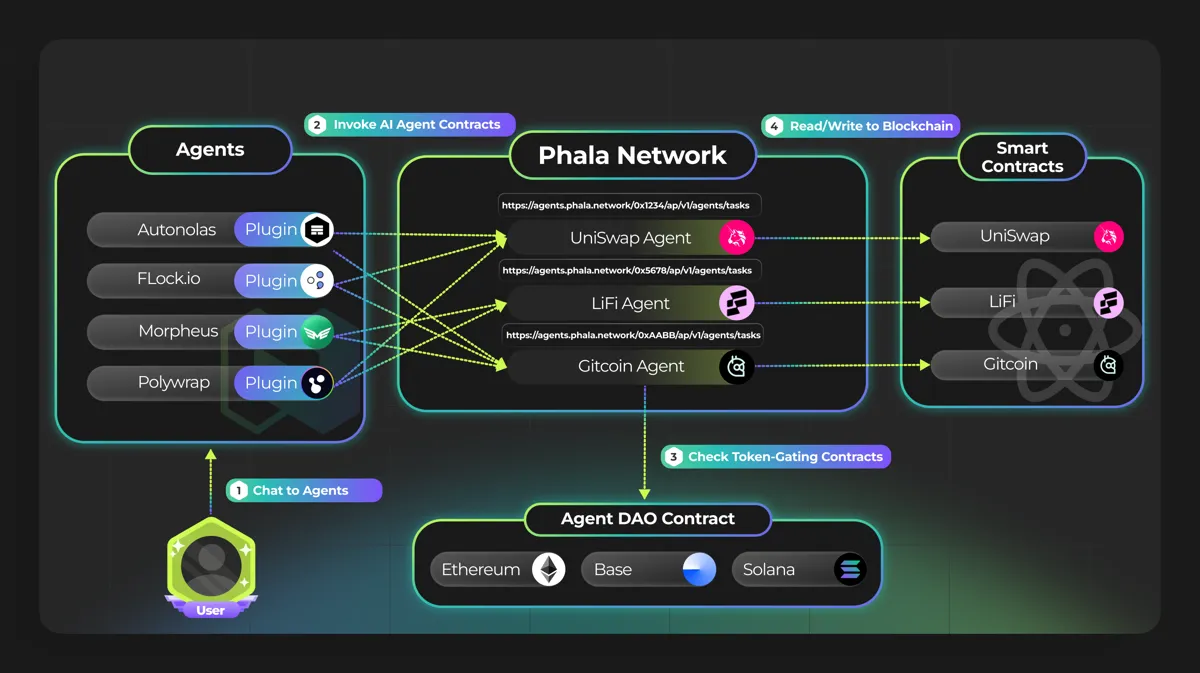
有趣之处:
充当可验证计算的协处理器协议,同时也使 AI 代理能够链上资源
其人工智能代理合约可通过 Redpill 获得 OpenAI、Llama、Claude 和 Hugging Face 等顶级大型语言模型
未来将包括 zk-proofs、多方计算 (MPC)、全同态加密 (FHE) 等多重证明系统
未来支持H100等其他TEE GPU ,提升计算能力
|
Render |
Akash |
io.net |
Gensyn |
Aethir |
Phala |
|
|
硬件 |
GPU & CPU |
GPU & CPU |
GPU & CPU |
GPU |
GPU |
CPU |
|
业务重点 |
图形渲染和AI |
云计算、渲染和AI |
AI |
AI |
人工智能、云游戏和电信 |
链上 AI 执行 |
|
AI任务类型 |
推理 |
Both |
Both |
训练 |
训练 |
执行 |
|
工作定价 |
基于表现的定价 |
反向拍卖 |
市场定价 |
市场定价 |
招标系统 |
权益计算 |
|
区块链 |
Solana |
Cosmos |
Solana |
Gensyn |
Arbitrum |
Polkadot |
|
数据隐私 |
加密&散列 |
mTLS 身份验证 |
数据加密 |
安全映射 |
加密 |
TEE |
|
工作费用 |
每项工作 0.5-5% |
20% USDC, 4% AKT |
2% USDC,0.25% 准备金费用 |
费用低廉 |
每个session 20% |
与质押金额成比例 |
|
安全 |
渲染证明 |
权益证明 |
计算证明 |
权益证明 |
渲染能力证明 |
继承自中继链 |
|
完成证明 |
- |
- |
时间锁证明 |
学习证明 |
渲染工作证明 |
TEE 证明 |
|
质量保证 |
争议 |
- |
- |
核实者和举报人 |
检查器节点 |
远程证明 |
|
GPU 集群 |
否 |
是 |
是 |
是 |
是 |
否 |
集群和并行计算的可用性
分布式计算框架实现了 GPU 集群,在不影响模型准确性的情况下提供更高效的训练,同时增强了可扩展性。训练更复杂的 AI 模型需要强大的计算能力,这通常必须依靠分布式计算来满足其需求。从更直观的角度来看,OpenAI 的 GPT-4 模型拥有超过 1.8 万亿个参数,在 3-4 个月内使用 128 个集群中的约 25,000 个 Nvidia A100 GPU 进行训练。
此前,Render 和 Akash 仅提供单一用途的 GPU,这可能会限制其对 GPU 的市场需求。不过,大多数重点项目现在都已整合了集群以实现并行计算。io.net 与 Render、Filecoin 和 Aethir 等其他项目合作,将更多 GPU 纳入其网络,并已成功在 24 年第一季度部署了超过 3,800 个集群。尽管 Render 不支持集群,但它的工作原理与集群类似,将单个帧分解为多个不同的节点,以同时处理不同范围的帧。Phala 目前仅支持 CPU,但允许将 CPU 工作器集群化。
将集群框架纳入 AI 工作流程网络非常重要,但满足 AI 开发人员需求所需的集群 GPU 数量和类型是一个单独的问题,我们将在后面的部分中讨论。
数据隐私
开发 AI 模型需要使用大量数据集,这些数据集可能来自各种来源,形式各异。个人医疗记录、用户财务数据等敏感数据集可能面临暴露给模型提供商的风险。三星因担心敏感代码上传到平台会侵犯隐私而内部禁止使用 ChatGPT,微软的 38TB 私人数据泄露事故进一步凸显了在使用 AI 时采取足够安全措施的重要性。因此,拥有各种数据隐私方法对于将数据控制权交还给数据提供商至关重要。
所涵盖的大多数项目都使用某种形式的数据加密来保护数据隐私。数据加密可确保网络中从数据提供者到模型提供者(数据接收者)的数据传输受到保护。Render 在将渲染结果发布回网络时使用加密和哈希处理,而 io.net 和 Gensyn 则采用某种形式的数据加密。Akash 使用 mTLS 身份验证,仅允许租户选择的提供商接收数据。
然而,io.net 最近与 Mind Network 合作推出了完全同态加密 (FHE),允许在无需先解密的情况下处理加密数据。通过使数据能够安全地传输用于培训目的而无需泄露身份和数据内容,这项创新可以比现有的加密技术更好地确保数据隐私。
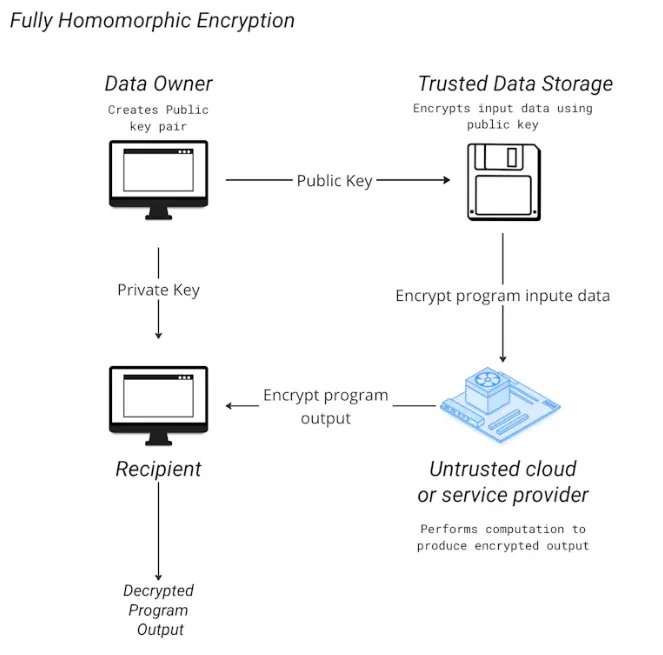
Phala Network 引入了 TEE,即连接设备主处理器中的安全区域。通过这种隔离机制,它可以防止外部进程访问或修改数据,无论其权限级别如何,即使是对机器具有物理访问权限的个人。除了 TEE 之外,它还在其 zkDCAP 验证器和jtee命令行界面中结合了 zk-proofs 的使用,以便与 RiscZero zkVM 集成的程序。
这些项目提供的 GPU 可为一系列服务提供计算能力。由于这些服务范围广泛,从渲染图形到 AI 计算,因此此类任务的最终质量可能不一定总是符合用户的标准。可以使用完成证明的形式来表示用户租用的特定 GPU 确实用于运行所需的服务,并且质量检查对请求完成此类工作的用户有益。
计算完成后,Gensyn 和 Aethir 都会生成证明以表明工作已完成,而 io.net 的证明则表明租用的 GPU 的性能已得到充分利用且没有出现问题。Gensyn 和 Aethir 都会对已完成的计算进行质量检查。对于 Gensyn,它使用验证者重新运行生成的证明的部分内容以与证明进行核对,而举报人则充当对验证者的另一层检查。同时,Aethir 使用检查节点来确定服务质量,对低于标准的服务进行处罚。Render 建议使用争议解决流程,如果审查委员会发现节点存在问题,则削减该节点。Phala 完成后会生成 TEE 证明,确保 AI 代理在链上执行所需的操作。
|
Render |
Akash |
io.net |
Gensyn |
Aethir |
Phala |
|
|
GPU数量 |
5600 |
384 |
38177 |
- |
40000+ |
- |
|
CPU数量 |
114 |
14672 |
5433 |
- |
- |
30000+ |
|
H100/A100数量 |
- |
157 |
2330 |
- |
2000+ |
- |
|
H100费用/小时 |
- |
$1.46 |
$1.19 |
- |
- |
- |
|
A100费用/小时 |
- |
$1.37 |
$1.50 |
$0.55 (预计) |
$0.33 (预计) |
- |
由于 AI 模型训练需要性能最佳的 GPU,因此他们倾向于使用 Nvidia 的 A100 和 H100 等 GPU,尽管后者在市场上的价格很高,但它们提供最佳质量。看看 A100 如何不仅能够训练所有工作负载,而且还能以更快的速度完成训练,这只能说明市场对这种硬件的重视程度。由于 H100 的推理性能比 A100 快 4 倍,因此它现在已成为首选 GPU,尤其是对于正在训练自己的 LLM 的大型公司而言。
对于去中心化的 GPU 市场提供商来说,要想与 Web2 同行竞争,它不仅要提供更低的价格,还要满足市场的实际需求。2023年,Nvidia 向中心化的大型科技公司交付了超过 50 万台 H100,这使得获取尽可能多的同等硬件以与大型云提供商竞争变得成本高昂且困难重重。因此,考虑这些项目可以以低成本带入其网络的硬件数量对于将这些服务扩展到更大的客户群非常重要。
虽然每个项目都在 AI 和 ML 计算方面有业务,但它们在提供计算的能力方面有所不同。Akash 总共只有 150 多个 H100 和 A100 单元,而 io.net 和 Aethir 则分别获得了 2000 多个单元。通常,从头开始预训练 LLM 或生成模型需要集群中至少 248 到 2000 多个 GPU,因此后两个项目更适合大型模型计算。
根据此类开发人员所需的集群大小,目前市场上这些去中心化 GPU 服务的成本已经比中心化 GPU 服务低得多。Gensyn 和 Aethir 都宣称能够以每小时不到 1 美元的价格租用相当于 A100 的硬件,但这仍需要随着时间的推移得到证明。
网络连接的 GPU 集群拥有大量 GPU,每小时成本较低,但与 NVLink 连接的 GPU 相比,它们的一个问题是内存受限。NVLink支持多个 GPU 之间的直接通信,无需在 CPU 和 GPU 之间传输数据,即可实现高带宽和低延迟。与网络连接的 GPU 相比,NVLink 连接的 GPU 最适合具有许多参数和大型数据集的 LLMS,因为它们需要高性能和密集计算。
尽管如此,对于那些具有动态工作负载需求或需要灵活性和跨多个节点分配工作负载能力的用户来说,去中心化 GPU 网络仍可为分布式计算任务提供强大的计算能力和可扩展性。通过提供比中心化云或数据提供商更具成本效益的替代方案,这些网络为构建更多 AI 和 ML 用例打开了寡头垄断局面,而不像中心化 AI 模型那样。
尽管 GPU 是渲染和计算所需的主要处理单元,但 CPU 在训练 AI 模型方面也发挥着重要作用。CPU 可用于训练的多个部分,包括数据预处理一直到内存资源管理,这对开发人员开发模型非常有用。消费级 GPU 还可用于不太密集的任务,例如对已经预先训练好的模型进行微调或以更实惠的成本在较小的数据集上训练较小规模的模型。
尽管 Gensyn 和 Aethir 等项目主要专注于企业级 GPU,但考虑到超过 85% 的消费者 GPU 资源处于闲置状态,Render、Akash 和 io.net 等其他项目也可以服务于这一部分市场。提供这些选项可以让他们开发自己的市场利基,让他们专注于大规模密集型计算、更通用的小规模渲染或两者之间的混合。
AI DePIN 领域仍然相对较新,面临着自身的挑战。他们的解决方案因其可行性而受到批评,并遭遇挫折。例如,io.net 被指控伪造其网络上的 GPU 号码,后来通过引入工作量证明流程来验证设备并防止女巫攻击,解决了这个问题。
尽管如此,这些去中心化 GPU 网络中执行的任务和硬件数量仍显着增加。这些网络上执行的任务量不断增加,凸显了对 Web2 云提供商硬件资源替代品的需求不断增长。同时,这些网络中硬件提供商的激增凸显了以前未充分利用的供应。这一趋势进一步证明了 AI DePIN 网络的产品市场契合度,因为它们有效地解决了需求和供应方面的挑战。
展望未来,人工智能的发展轨迹指向一个蓬勃发展的数万亿美元的市场,我们认为这些分散的 GPU 网络将在为开发人员提供经济高效的计算替代方案方面发挥关键作用。通过利用其网络不断弥合需求和供应之间的差距,这些网络将为人工智能和计算基础设施的未来格局做出重大贡献。








